Abstract
The 3D reconstruction technology has become an integral part of our daily lives and various industries, and UNIST's research team has continued to advance its development. Known as DITTO (Dual and Integrated Latent Topologies), the precise 3D modeling technology developed by Professor Kyungdon Joo and his research team in the Graduate School of Artificial Intelligence at UNIST, has opened up new possibilities for the restoration of cultural heritage properties.
DITTO leverages the strengths of both point cloud and grid methods to reconstruct object shapes, converting point cloud data into a grid and leveraging both data simultaneously to extract important information. The Dynamic Spare Point Transformer (DSPT) analysis tool is used to precisely analyze point cloud data and extract features that can accurately model complex and thin objects.

Figure 1. Overview of DITTO.
This technology has demonstrated significant potential for improving 3D modeling accuracy in various industries, such as medicine, robotics, and virtual reality. Based on the extracted data, the Integrated Implicit Decoder (IID) predicts whether a specific location in 3D space is inside or outside an object, enabling more accurate and detailed 3D reconstruction compared to existing technology.
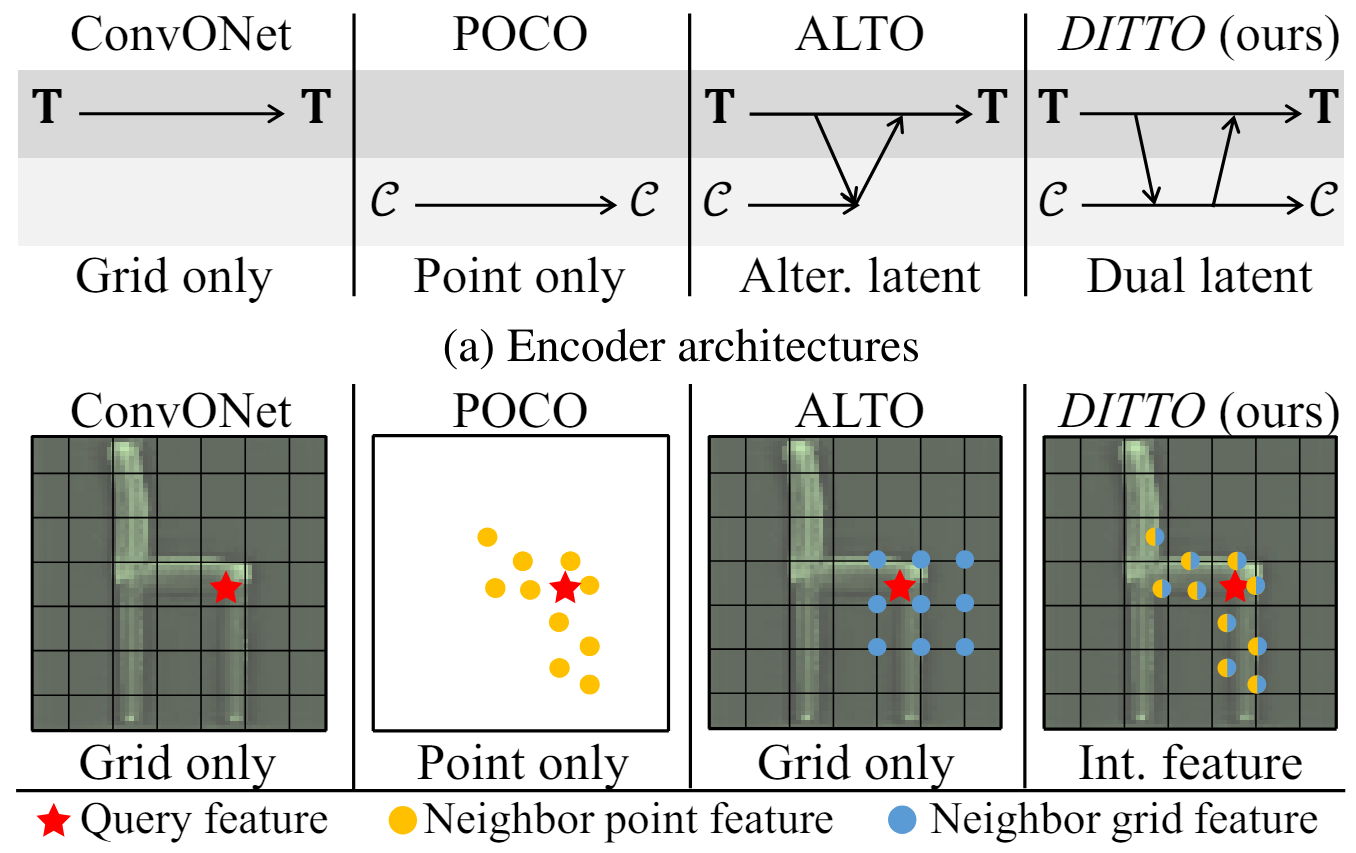
Figure 2. Conceptual comparison of DITTO
The improved 3D modeling technology also has the potential to precisely restore damaged or deteriorated cultural heritage properties, preserving their original forms and details. According to Professor Kyungdon Joo, "This study goes beyond simply increasing the accuracy of 3D reconstruction and presents a new method for utilizing 3D data in various technologies. This will be a valuable tool for industries such as metaverse and CAD/CAE as a whole."
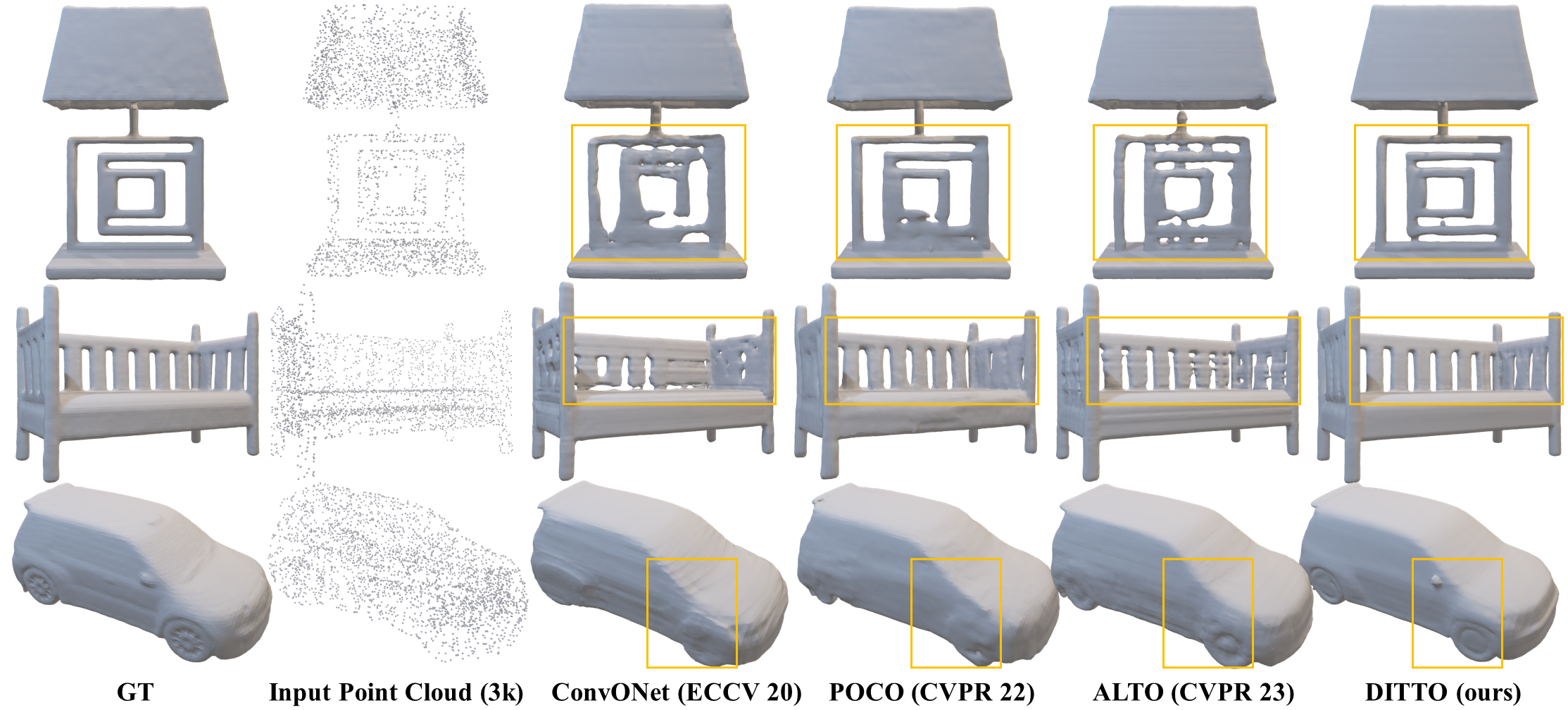
Figure 3. Object-level 3D reconstruction comparison on ShapeNet with 3K input points.
First author Jaehyeok Shim added, "This technology offers a new way to express 3D data, which holds significant potential for technological development. Collaboration with various academia and industries will play a crucial role in driving this technological advancement."
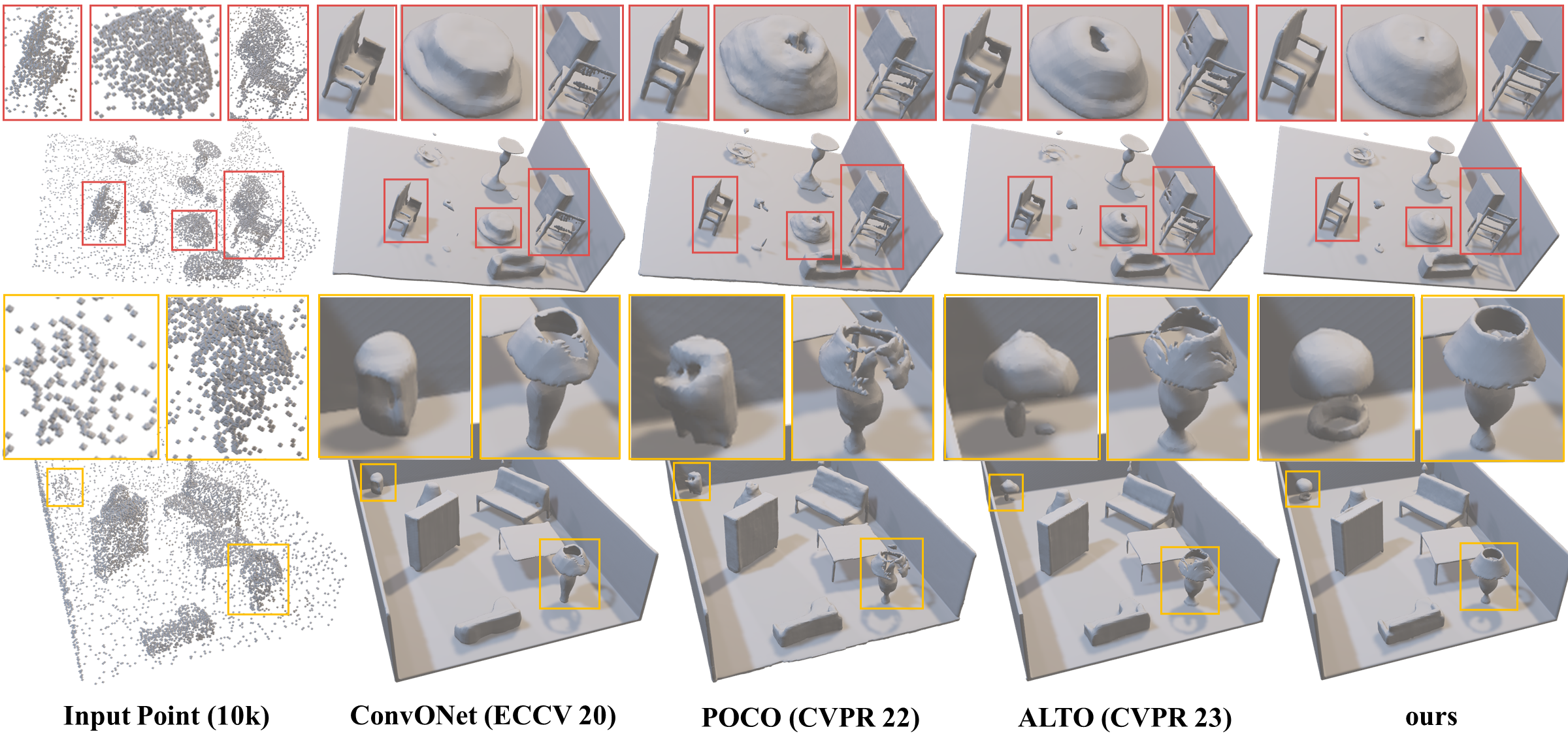
Figure 4. Qualitative comparison of scene-level 3D surface reconstruction on the Synthetic Rooms dataset.
The research findings will be presented on June 21 at the CVPR 2024, a global computer vision conference scheduled to take place from June 17 to 21 in Seattle, U.S.A. The research team anticipates that the improved accuracy of DITTO technology could lead to cost savings and increased efficiency in industries such as construction, architecture, and manufacturing.
Journal Reference
Jaehyeok Shim and Kyungdon Joo, "DITTO: Dual and Integrated Latent Topologies for Implicit 3D Reconstruction," CVPR, (2024).





