Processing and analysing the quality of 2023 Census data describes how the 2023 Census data was processed and analysed, following data collection activity, to produce a final dataset for public release.
Contents
- Summary
- Strategic initiatives of the census programme
- Developing a new processing system
- Analysing the data collection process
- Final dataset
- Glossary
Summary
The information that people submit in their completed census forms needs to be processed and analysed to produce data that can be used by a range of customers. Customers use census data to understand the current composition of the national population (such as who we are, where we live, our housing, and educational and employment situations) and drive any interventions that may be required to support our changing demographics.
The 2023 Census took place on 7 March 2023. While information from online submissions went straight to the processing stage, completed paper forms were scanned, and handwritten responses were then translated to a compatible electronic format. A proportion of remaining unclear and ambiguous responses were then manually checked by a data specialist to ensure they were recorded (coded) accurately.
A new system was developed for data processing, building on knowledge gained from 2018 Census to include administrative (admin) data by design.
After people submitted their completed census forms, we used automated and manual processes to:
- combine 2023 Census data with 2013 and 2018 Census and admin data to improve the final census count
- apply data transformations, add manual data edits, and create metadata
- add data where there were missing values
- create regular datasets for continuous data quality analysis and eventual release to the public.
Strategic initiatives of the census programme
The work to process and analyse the 2023 Census data focused on supporting two of the strategic initiatives in the 2023 Census strategy.
Strategic initiative 2: Deliver quality data to meet customer needs
Enabled by:
- having clarity of customers' needs
- quality by design
- independent verification.
Strategic initiative 4: Built trust and value for Māori through data equity
Enabled by:
- building capacity and capability for iwi-Māori
- collaborating with iwi-Māori to deliver quality data
- establishing co-design partnerships.
Developing a new processing system
The 2023 Census design included some key changes to build on from the previous censuses:
- a combined collection model with greater use of paper forms
- increased paper-form scanning repair to include more questions
- increased scope of manual processing to include more variables
- dedicated specialist manual-processing teams for complex topics, such as iwi and family coding
- improvements on combining census-form responses with admin data to adjust for missing people and information
- improvements to alternative data sourcing and statistical imputation, covering more variables with better data sources where possible.
These design changes impacted the core processing of data. A suite of separate, independent routines as developed to process each variable from the Response Store (the database that holds the raw responses from census forms) to the final output variable in the Census Unit Record File (CURF). The routines were tested, modified, added, or deleted as required in a controlled and measured manner.
The alternative data sources we used
Missing information and missing people are common issues in census collection where a respondent did not complete a census form or did not provide an answer to a question, or responded in a way that is not usable (such as illegible or incoherent). Using alternative data sources to fill these gaps leads to a more representative final census dataset.
The alternative data sources we used included the 2013 and 2018 Census and admin data from the Integrated Data Infrastructure (IDI) research database. In 2023 Census, the range of admin data sources was expanded from 2018, and a wider range of variables have admin data as an alternative data source.
Information on our approach for the use of alternative data sources in the 2023 Census dataset is available in:
- Data sources and imputation for Māori descent in the 2023 Census
- Editing, data sources, and imputation in the 2023 Census
- Linking 2023 Census responses to the Integrated Data Infrastructure
- Methodologies for filling gaps in gender and sex at birth concepts for the 2023 Census
- Methodology for using admin data to count people in the 2023 Census
- Predicting usual residence address from admin data in the 2023 Census.
Information on our approach will also be available in the upcoming publications (note, titles and release dates are prospective and subject to change):
- Data sources and methodology for iwi affiliation in the 2023 Census (26 September 2024)
- Data sources and imputation for cigarette smoking behaviour in the 2023 Census (early October 2024)
- Families and households in the 2023 Census: Data sources, family coding, and data quality (31 October 2024)
- 2023 Census - Families and households by ethnicity - methodology (31 October 2024)
- Summary of the admin data used in the 2023 Census dataset (31 October 2024).
The 2023 Census processing system
Routines were written in the Python programming language (2018 Census was written in R language and Pentaho code). The use of Python supported building in modular processing steps and the reuse of code via central libraries. The existing 2018 household and families module, written in C++ language, was reused.
The underlying enterprise infrastructural technologies of the 2023 Census data-processing system did not change from 2018. The 2023 Census data-processing system utilised the following Enterprise Processing Integrated Capability (EPiC) technologies:
- Response Store
- Datastore
- Enterprise Manual Intervention Service
- Ariā and Colectica (corporate metadata repositories).
Key principles of the system were continuous processing, regular data quality analysis feedback, and flexibility around content and specification changes. Once we had captured the census response data from online and had scanned paper forms, we used automated and manual processes to:
- combine 2023 Census data with 2013 and 2018 Census and admin data (including linking address information) to improve the final census count
- apply data transformations (linking, coding, editing, and derivations), add manual data edits, and create metadata (for example, adding 'flags' to the data to identify its source and improve its usefulness)
- add data where there were missing values using the CANCEIS tool (CANadian Census Edit and Imputation System), probabilistic imputation (using data from other people in the household), and historical census data
- add improved paradata, providing information about how the data was processed to support debugging, quality analysis and to enable clear tracking of data through the system (transparent data provenance)
- provide continuous regular delivery of Census Unit Record Files (CURFs) to support ongoing analysis and data improvement and eventual release to the public.
Every run was regression tested, which allowed us to compare current versions of the data with previous versions to assess the impact of changes on the CURFs and manage unintended change.
The logic blocks
The processing system was built in a modular fashion over 10 'logic blocks'. These consecutive data processing steps each involved their own series of processes. Originally based on 2018 Census design, the use of configuration files meant that the order of processing logic blocks could be easily updated as the project progressed.
Logic blocks in the processing system (listed in the order they were executed) |
|
Logic block |
Process |
1 |
Read in dwelling and individual responses, dwelling address coding |
2 |
Individual address coding and key variable coding |
3 |
Person unit reconciliation and repatriation |
4 |
Prepare data for admin linking and export file; ingest admin |
7 |
Process remaining dwelling variables - impute missing data |
8 |
Create household matrix - impute missing data (CANCEIS) |
5 |
Attribute sourcing - impute missing data (CANCEIS) for individuals |
6 |
Process remaining individual variables |
9 |
Family and household derivations |
10 |
Generate CURF datasets and paradata logs |
Further explanation of each logic block is provided in the next section. Once these logic blocks were completed, we transformed the raw data into clean unit records, applied confidentiality keys, and produced final datasets.
Figure 1 provides a high-level summary of the process followed through the 10 logic blocks to generate the Census Unit Record File (CURF).
Figure 1
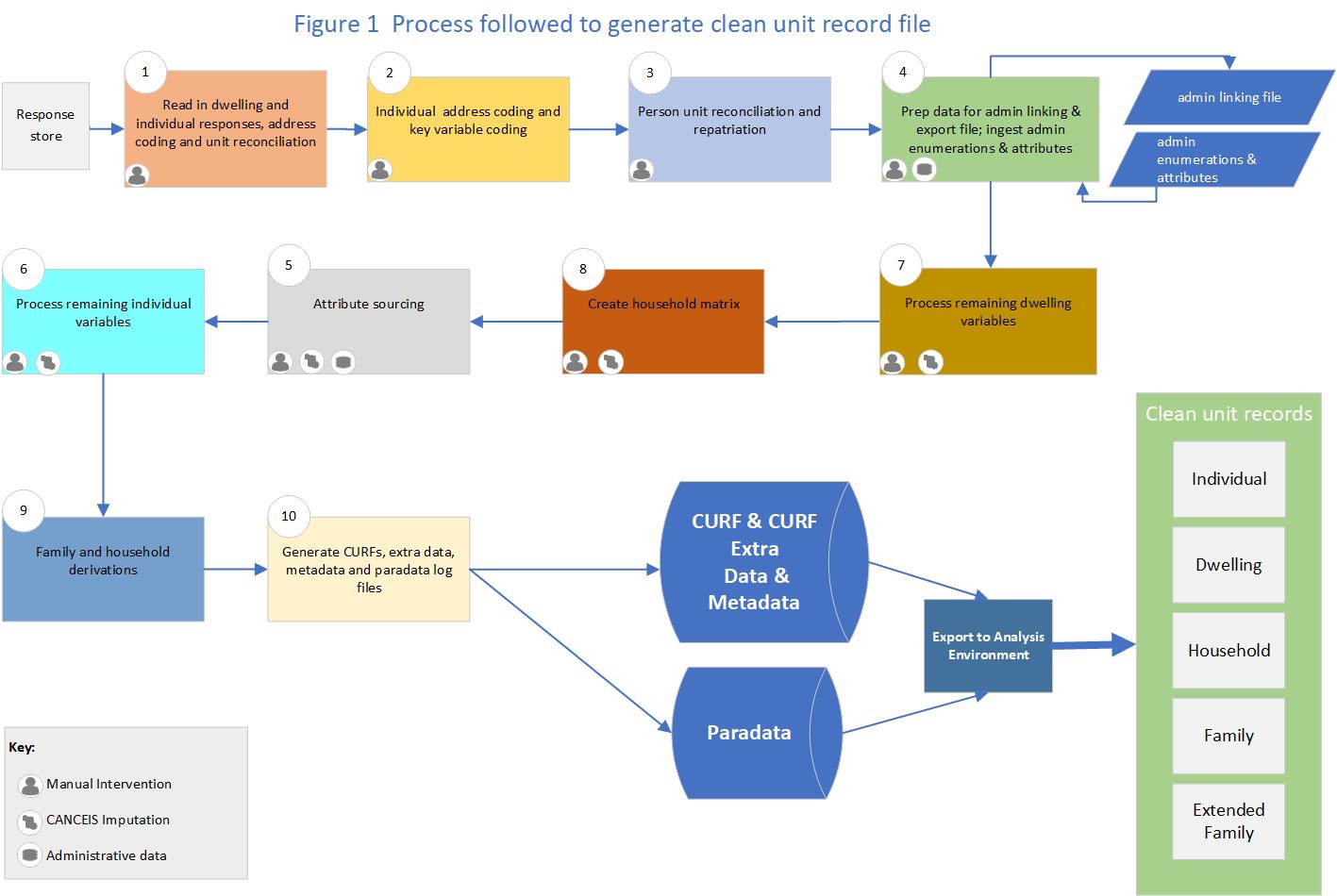
Key activities for each logic block
Note: manual and automated processing edits took place as required across the logic blocks.
Logic block 1 - Read in dwelling and individual responses, dwelling address coding and unit reconciliation:
- read in dwelling and individual responses
- remove facetious or invalid responses
- remove duplicate dwelling responses
- create the processing operational frame for dwellings
- code key dwelling variables (for example, dwelling address, dwelling description, dwelling joined or separate, number of storeys, occupancy status and derive dwelling type).
Logic block 2 - Individual address coding and key variable coding:
- code key individual variables (for example, usual residence address, census night address, usual residence one year ago, age, gender, sex at birth, and derive address indicators).
Logic block 3 - Person unit reconciliation and repatriation:
code key individual variables from dwelling form (for example, age, gender, and relationship to reference person)
- code dwelling record type
- deduplicate person records and identify links between individual forms and people listed on the dwelling form
- link individual forms to dwelling forms (reconciliation), then to both census night address and usual residence address (repatriation).
Logic block 4 - Prepare data for admin linking and export file; ingest admin and admin attributes:
- code additional individual variables required for admin linking (for example, birthplace and person record type) and export file ready for admin linking in the dedicated admin linking environment
- after admin linking is completed, read admin enumerations and attributes and combine with response data (admin data is applied throughout subsequent logic blocks)
- probabilistic imputation of age and date of birth.
Logic block 7 - Process remaining dwelling variables - impute missing data (CANCEIS):
- code other dwelling variables (for example, tenure of household, rent indicator, number of rooms, main types of heating, and access to basic amenities)
- carry out CANCEIS imputation for other dwelling variables.
Logic block 8 - Create household matrix - impute missing data (CANCEIS):
- create household matrix - transitive closure (all people in a household were put into a matrix of relationships to others in the household)
- carry out CANCEIS and non-CANCEIS imputation for the household matrix.
Logic block 5 - Attribute sourcing - impute missing data (CANCEIS):
- code more variables (for example, ethnic group, iwi, Māori descent, total personal income, status in employment, and workplace address)
- carry out CANCEIS imputation.
Logic block 6 - Process remaining individual variables:
- code remaining individual variables (for example, activity limitations, disability indicator, ethnic group derivations, and sexual identity)
- carry out remaining CANCEIS imputation.
Logic block 9 - Family and household derivations:
- apply consistency edits and other variable edits
- code family and household derivations.
Logic block 10 - Upload CURF datasets and paradata logs:
- upload CURF datasets and paradata logs to the EPIC datastore
- extract data for operational intelligence reporting.
Manual processing
A key part of the 2023 Census data processing was to investigate and manually repair (where possible) any data issues that could not be resolved by automated processing.
Manual operators checked and fixed responses flagged for manual quality checks to determine a respondent's intentions and/or resolve edit failures, particularly where complex decisions were required, for example, around determining family relationships (family coding).
The manual processing operation ran from March to May 2024, involving more than 60 full-time staff (during peak processing operations). When they had completed the manual corrections, we loaded the data back into the dataset to be included in the ongoing automated processing operation and for data analysis. Items were prioritised by considering the variable's priority rating (priority level 1, 2, or 3), the dependencies on other processes (admin linking), and the ability to repair the issue.
More manual processing was performed for some steps in 2023 compared with 2018 (for example, iwi coding, linking of individuals to dwellings, and family coding) to improve the quality of data.
Adding metadata flags to the data
Metadata flags were added to the data to give internal and external users clarity around the sources that we used to determine the combined output for a census variable.
Tables 2 and 3 outline the levels and codes applied to the individual and item data sources.
Individual unit record source, 2023 Census |
|||||
Level 1 |
Level 2 |
Level 3 |
|||
Code |
Descriptor |
Code |
Descriptor |
Code |
Descriptor |
1 |
Response |
11 |
2023 Census |
111 |
2023 Census |
1 |
Response |
12 |
Individuals on the |
121 |
Individuals on the |
1 |
Response |
12 |
Individuals on the |
122 |
Field-enumerated |
2 |
Admin |
21 |
Admin |
211 |
Admin |
2 |
Admin |
21 |
Admin |
212 |
Admin |
2 |
Admin |
21 |
Admin |
213 |
Admin |
2 |
Admin |
21 |
Admin |
214 |
Admin (unoccupied, |
2 |
Admin |
21 |
Admin |
215 |
Admin |
2 |
Admin |
21 |
Admin |
216 |
Admin |
2 |
Admin |
21 |
Admin |
217 |
Admin |
2 |
Admin |
21 |
Admin |
218 |
Admin |
Item source indicators, 2023 Census |
|||
Level 1 |
Level 2 |
||
Code |
Descriptor |
Code |
Descriptor |
1 |
2023 Census response |
11 |
2023 Census form |
1 |
2023 Census response |
12 |
2023 Census individual variable |
2 |
Historical census |
21 |
2018 Census |
2 |
Historical census |
22 |
2013 Census |
3 |
Admin data |
31 |
Admin data |
5 |
Deterministic derivation |
51 |
Deterministic derivation |
6 |
Statistical imputation |
41 |
Probabilistic imputation |
6 |
Statistical imputation |
61 |
CANCEIS donor's response |
6 |
Statistical imputation |
62 |
CANCEIS donor's response |
6 |
Statistical imputation |
63 |
CANCEIS donor's response |
6 |
Statistical imputation |
64 |
CANCEIS donor's response |
6 |
Statistical imputation |
65 |
CANCEIS donor's response |
6 |
Statistical imputation |
66 |
CANCEIS donor's response |
6 |
Statistical imputation |
67 |
CANCEIS donor's response |
7 |
No information |
71 |
No information |
Analysing the data collection process
Concurrent to processing, the census data was analysed to check it provided quality data that would be fit for purpose. This involved continuous, regular delivery of processed datasets to support ongoing analysis, feedback, and improvement of the dataset throughout the analysis period.
Census variables were assessed and analysed to produce guideline ratings using a quality assessment framework and a quality rating scale.
Data quality assurance in the 2023 Census provides more information on the quality rating scale and the quality framework.
Data warrants of fitness
We used a warrant of fitness (WOF) process to analyse each census variable following the quality assessment framework. WOFs help ensure we provide consistent information about the quality of each census variable. While we don't publish WOF documentation, we use it to produce the 'Information by concept' documentation.
Information by concept has more information.
2018 external data quality panel recommendations were incorporated to the WOF process where relevant to ensure the quality assessment was performed in a systematic and consistent way for all 2023 Census data concepts, and that we can provide more data quality information for data users. We also consulted with iwi-Māori data experts during the WOF process to ensure we are meeting our strategic goal of collaborating with iwi-Māori to deliver quality data.
During the WOF process, we:
- analysed the data; this included:
- checks of the composition of data and data sources
- time series checks, comparing the data to previous censuses and other information for coherence over time
- checks against expectations and assessments of how well the data reflects real world change
- checks at appropriate levels of the classification (usually down to the lowest level)
- checks at appropriate levels of geography (usually down to SA2)
- checks by age, gender, ethnicity (level 1), and Māori descent where applicable
- consistency checks
- checks of key crosstabs with other variables
- completing an outline of the edits, including data edits
- assigned a quality rating to each variable, with supporting rationale
- made recommendations for using the data (including recommendations for the next census).
Warrant of fitness quality processes
The 2023 WOF process built on the process from the 2018 Census and incorporated recommendations from the external data quality panel review. To identify and fix data issues, our WOF process involved:
- the use of internal variable experts and census topic-owner analysts
- raising and presenting data problem reports to an internal problem-monitoring group and an internal advisory group, who:
- weighed up the costs and benefits of resolution options for data quality issues
- recommended a resolution option.
The WOFs individually and collectively went through a quality assurance process to check:
- each WOF was produced correctly (for example, the correct data was being assessed)
- the analysis was complete and correct
- the data assessment was accurately reflected in commentaries and the final quality rating
- consistency of analysis and quality ratings across the suite of WOFs.
Data quality assurance in the 2023 Census provides more information on the quality assessment framework analysis.
Final dataset
Once we had analysed the dataset, we re-ran the processing system, applied the confidentiality process, set the final population group numbers, and produced a final dataset for public use: the Census Unit Record File (CURF).
Glossary
Admin enumeration - the use of admin data to add people to the usually resident census population when a census response has not been received.
Administrative data (admin data) - data collected by government or other organisations for non-statistical reasons, such as births, tax, health, and education records.
CANadian census editing and imputation system (CANCEIS) - the editing and imputation tool created by Statistics Canada for use with their census. We have configured CANCEIS for Stats NZ census data.
Census Unit Record File (CURF) - the datasets of individuals, dwellings, households, families, and extended families.
Coding - the process by which a description of an item or activity supplied as a survey response is matched to the code of a classification category. The coded categories are defined in standard and census-specific classifications.
Confidentiality - The Data and Statistics Act 2022 requires Stats NZ and its employees to protect the identity of individuals and organisations contained within statistical outputs. To achieve this, we use a variety of confidentiality techniques to protect individuals and organisations from harm and to maintain public trust in our work.
Applying confidentiality rules to 2023 Census data and summary of changes since 2018 and 2013 Censuses has more information.
Confidentiality key - a random number assigned to each census record to enable fixed random rounding of counts and to add noise (random irregularities) to measures to protect against disclosure.
Derivation - a variable that is created or calculated from one or more other variables, for example, a person's age is derived from their date of birth.
Deterministic derivation - when a value from a census variable can be used to inform a missing value in another census variable. For example, a valid 'Iwi affiliation' value can be used to inform a value for 'Māori descent'.
Edit - detecting, and in some cases resolving, wrong and/or illogical responses to census fields.
Family coding - either a couple, a couple with children, or a solo parent with children. The family coding process identifies these groups within households and others in the household who are related to them and creates output derivations for demographics about the groups.
Historical data - data sourced from 2018 and 2013 Censuses.
Imputation - in statistics, the process of replacing missing data with estimated values through statistical methods. For the 2023 Census, the method for estimating values was the nearest neighbour imputation methodology (NIM), which finds similar respondents with a response to the variable in question. The processing system then finds the closest match to the respondent with missing or unidentifiable data ('donor respondents') and imputes the donor respondent's response. This method of imputation uses CANCEIS, developed by Statistics Canada and used in their census. See also 'item imputation'.
Integrated Data Infrastructure (IDI) - a large research database that holds microdata about people and households. The data in the IDI comes from government agencies, Stats NZ surveys, and non-governmental organisations (NGOs). The data is linked or integrated to form the IDI.
Item imputation - the statistical process of determining a value for a variable where a response was missing (item non-response) or not usable (for example, response unidentifiable). Item imputation is carried out for individuals, dwellings, households, and families.
Logic block - a set of routines and tasks grouped together from a business logic perspective (called modules in 2018).
Operational dwelling frame (ODF) - a list of all private and non-private dwellings in New Zealand, used during the census.
Reconciliation (or forms reconciliation) - the process of determining if all forms have been received for an occupied dwelling (or, if not, how many forms are outstanding).
Repatriation - transferring all records of individuals who are away from home on census night into the record on their dwelling of usual residence.
Routine - a portion of code within a larger program that performs a specific task and is relatively independent of the remaining code.
Statistical imputation - the process of replacing missing data with estimated values from a statistical process (in contrast to sourcing real values from admin or historical census data). The purpose is to provide realistic values for missing data for individuals. For the 2023 Census, the method used was nearest-neighbour donor imputation (NIM). This finds respondents with a response to the variable in question who are similar to the respondent with missing or unidentifiable data, and copies over their response for the missing variable. This method of imputation uses CANCEIS, developed by Statistics Canada and used in their census as well as by many other statistical agencies around the world.
Transitive closure - The process of completing the household matrix logically from the relationship to reference person information.
Text alternative for figure 1
Figure 1 outlines the process followed to generate a clean unit record file. The flow chart shows the process through the 10 logic blocks from the Response Store to the analysis environment to generate clean unit records for individual, dwelling, household, family, and extended family variables.
ISBN 978-1-991307-07-1





